 八零岁月
八零岁月高并发系统各不相同,比如每秒百万并发的中间件系统、每日百亿请求的网关系统、瞬时每秒几十万请求的秒杀大促系统。 他们在应对高并发的时候,因为系统各自自身特点的不同,所以应对架构都是不一样的。 所以这里只是提供大部分系统支撑高并发的思路,供大家学习参考。
验证机制的演进
进入正题之前,先来介绍一下session,token。个人觉得这个是任何高并发系统都会涉及的。这里不分享他们的概念,只是给大家分享为什么高并发一定会涉及这两个。
- 最初Web应用的兴起,像在线购物网站,需要登录的网站等等,马上就面临一个问题,那就是要管理会话,必须记住哪些人登录系统, 哪些人往自己的购物车中放商品, 也就是说我必须把每个人区分开,这就是一个不小的挑战,因为HTTP请求是无状态的,所以想出的办法就是给大家发一个会话标识(session id), 说白了就是一个随机的字串,每个人收到的都不一样, 每次大家向我发起HTTP请求的时候,把这个字符串给一并捎过来, 这样我就能区分开谁是谁了。
- 这样问题解决了,可是服务器就遇到一个问题,每个人只需要保存自己的session id,而服务器要保存所有人的session id !如果访问服务器多了, 就得由成千上万,甚至几十万个。这对服务器说是一个巨大的开销 , 严重的限制了服务器扩展能力, 比如说我用两个机器组成了一个集群, 小F通过机器A登录了系统, 那session id会保存在机器A上, 假设小F的下一次请求被转发到机器B怎么办?机器B可没有小F的 session id啊。
- 当然你会跟我说把session id 集中存储到一个地方, 所有的机器都来访问这个地方的数据, 这样一来,就解决此问题了, 但是增加了单点失败的可能性, 要是那个负责session 的机器挂了, 所有人都得重新登录一遍。
- 最后你会不会想做一个集群,增加可靠性, 但不管如何, 这小小的session 对于我们来说都是一个沉重的负担。
- 那有没有更好的解决问题的思路,比如说, 小F已经登录了系统, 我给他发一个令牌(token), 里边包含了小F的 user id, 下一次小F 再次通过Http 请求访问我的时候, 把这个token 通过Http header 带过来不就可以了。不过这和session id没有本质区别啊, 任何人都可以可以伪造, 所以想点儿办法, 让别人伪造不了,比如对数据做一个签名吧, 用HMAC-SHA256 算法()(其他加密算法也可以,注意,一定要对称加密算法,否则像md5不可逆的,加了密自己都不知道是什么),加上一个只有我才知道的密钥, 对数据做一个签名, 把这个签名和数据一起作为token , 由于密钥别人不知道, 就无法伪造token了。
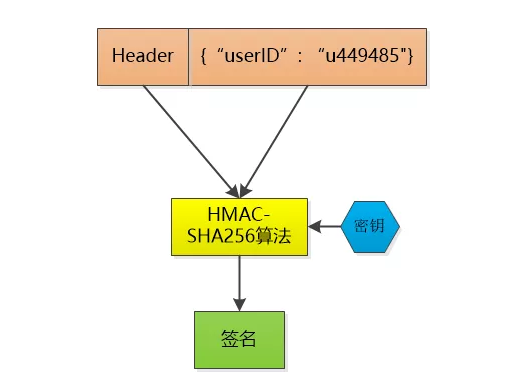
- 这个token 我不保存, 当小F把这个token 给我发过来的时候,我再用同样的HMAC-SHA256 算法和同样的密钥,对数据再计算一次签名, 和token 中的签名做个比较, 如果相同, 我就知道小F已经登录过了,并且可以直接取到小F的user id , 如果不相同, 数据部分肯定被人篡改过, 我就告诉发送者:对不起,没有认证。
- 到此也就解除了服务器存储session id这个负担, 我的集群现在可以轻松地做水平扩展, 用户访问量增大, 直接加机器就行。这种无状态的感觉是不是很好!
- token是否安全。Token 中的数据是明文保存的(当然你也可以用Base64做下编码) 如果一个人的token 被别人偷走了, 那也没办法, 只能认为小偷就是合法用户, 这其实和一个人的session id 被别人偷走是一样的,其实没有什么安全不安全的。唯一的解决方法生成的token包含过期参数,比如token有效期7天,7天之后服务器解密 token 的过期参数,如果超过了7天强制失效。
最后总结一下
- Seesion:每次认证用户发起请求时,服务器需要去创建一个记录来存储信息。当越来越多的用户发请求时,内存的开销也会不断增加。
- 无状态,可扩展性:在服务端的内存中使用Seesion存储登录信息,伴随而来的是可扩展性问题。
- CORS(跨域资源共享):当我们需要让数据跨多台移动设备上使用时,跨域资源的共享会是一个让人头疼的问题。在使用Ajax抓取另一个域的资源,就可以会出现禁止请求的情况。
好了,介绍了这么多,我们开始进入正题吧。
网站雏形,单点系统
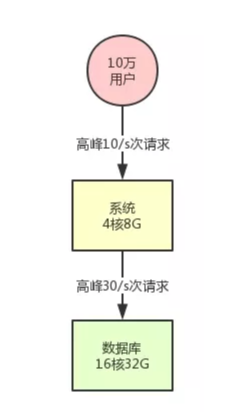
假设网站在起步阶段,刚刚开始你的系统就部署在一台机器上,背后就连接了一台数据库,数据库部署在一台服务器上。我们甚至可以再现实点,给个例子,你的系统部署的机器是 4 核 8G,数据库服务器是 16 核 32G。
此时假设你的系统用户量总共就 10 万,用户量很少,日活用户按照不同系统的场景有区别,我们取一个较为客观的比例,10% 吧,每天活跃的用户就 1 万。
按照 28 法则,每天高峰期算他 4 个小时,高峰期活跃的用户占比达到 80%,就是 8000 人活跃在 4 小时内。然后每个人对你的系统发起的请求,我们算他每天是 20 次吧。那么高峰期 8000 人发起的请求也才 16 万次,平均到 4 小时内的每秒(14400 秒),每秒也就 10 次请求。
然后系统层面每秒是 10 次请求,对数据库的调用每次请求都会好几次数据库操作的,比如做做 crud 之类的。那么我们取一个一次请求对应 3 次数据库请求吧,那这样的话,数据库层每秒也就 30 次请求,对不对?按照这台数据库服务器的配置,支撑是绝对没问题的。
好吧!完全跟高并发搭不上边,对不对?不着急一步一步给你介绍。
上述描述的系统,用一张图表示,就是下面这样:
系统集群化部署
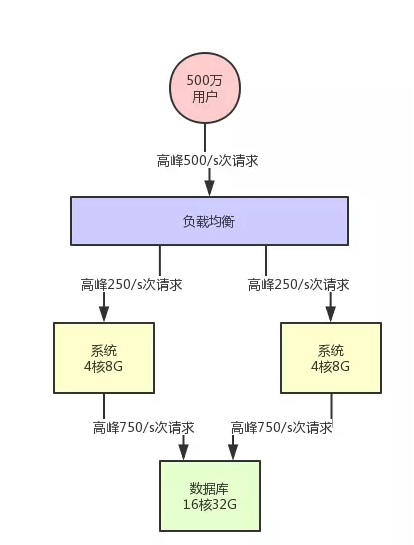
假设此时你的用户数开始快速增长,比如注册用户量增长了 50 倍,上升到了 500 万。此时日活用户是 50 万,高峰期对系统每秒请求是 500/s。然后对数据库的每秒请求数量是 1500/s,这个时候会怎么样呢?
按照上述的机器配置来说,如果你的系统内处理的是较为复杂的一些业务逻辑,是那种重业务逻辑的系统的话,是比较耗费 CPU 的,当前的服务器配置可能勉强支撑,但是碰到爆点的时候,就有点心有余而力不足了。
所以此时你需要做的一个事情,首先就是要支持你的系统集群化部署。你可以在前面挂一个负载均衡层,把请求均匀打到系统层面,让系统可以用多台机器集群化支撑更高的并发压力。比如说这里假设给系统增加部署一台机器,那么每台机器就只有 250/s 的请求了。
所以,简单小结,第一步要做的:
- 添加负载均衡层,将请求均匀打到系统层。
- 系统层采用集群化部署多台机器,扛住初步的并发压力。
此时的架构图变成下面的样子:
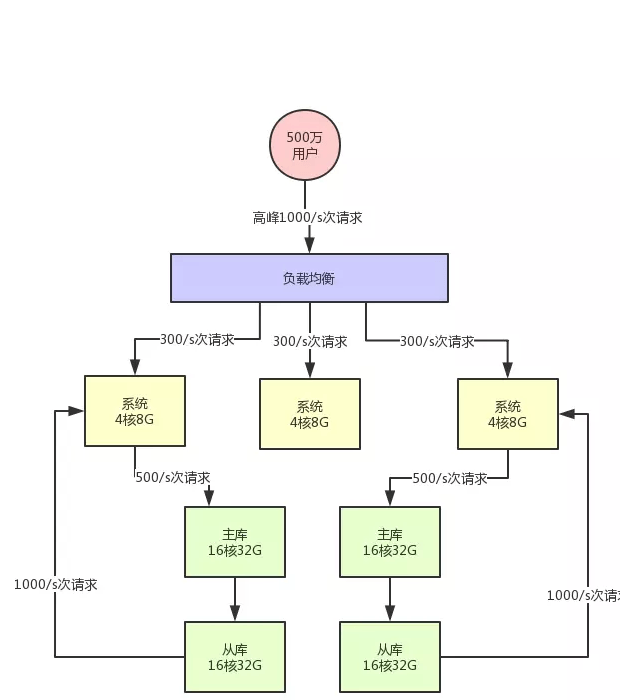
数据库分库分表 + 读写分离
假设此时用户量继续增长,达到了 1000 万注册用户,然后每天日活用户是 100 万。
那么此时对系统层面的请求量会达到每秒 1000/s,系统层面,你可以继续通过集群化的方式来扩容,反正前面的负载均衡层会均匀分散流量过去的。但是,这时数据库层面接受的请求量会达到 3000/s,这个就有点问题了。此时数据库层面的并发请求翻了一倍,你一定会发现线上的数据库负载越来越高。
因为数据库压力过大,首先一个问题就是高峰期系统性能可能会降低,因为数据库负载过高对性能会有影响。 另外一个,压力过大把你的数据库给搞挂了怎么办? 所以此时你必须得对系统做分库分表 + 读写分离,也就是把一个库拆分为多个库,部署在多个数据库服务上,这是作为主库承载写入请求的。 然后每个主库都挂载至少一个从库,由从库来承载读请求。
此时假设对数据库层面的读写并发是 3000/s,其中写并发占到了 1000/s,读并发占到了 2000/s。 那么一旦分库分表之后,采用两台数据库服务器上部署主库来支撑写请求,每台服务器承载的写并发就是 500/s。每台主库挂载一个服务器部署从库,那么 2 个从库每个从库支撑的读并发就是 1000/s。
简单总结,并发量继续增长时,我们就需要在数据库层面:分库分表、读写分离。
此时的架构图变成下面的样子:
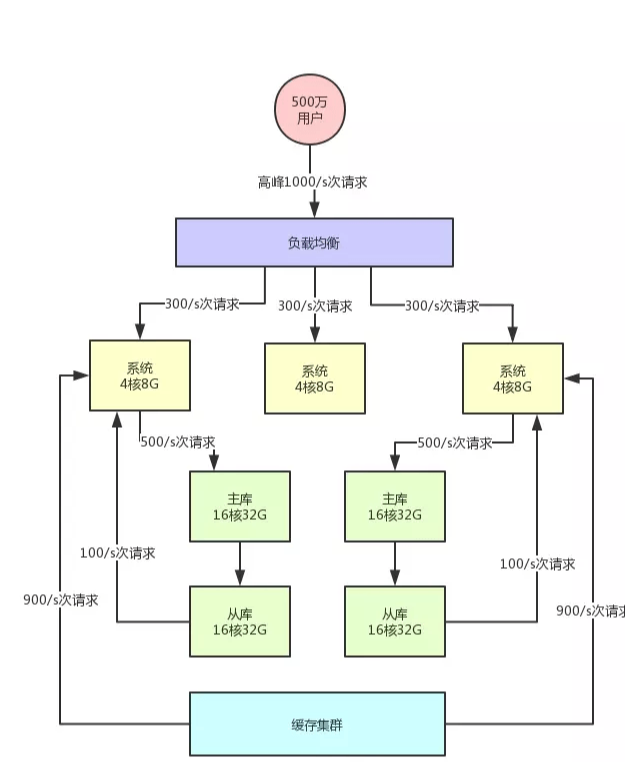
缓存集群引入
接着就好办了,如果你的访问用户量越来越大,此时你可以不停的加机器,比如说系统层面不停加机器,就可以承载更高的并发请求。
但是这里有一个很大的问题:数据库其实本身不是用来承载高并发请求的,所以通常来说,数据库单机每秒承载的并发就在几千的数量级,而且数据库使用的机器都是比较高配置,比较昂贵的机器,成本很高。如果你就是简单的不停的加机器,其实是不对的。
还有一个问题就是没钱加服务器啊。
所以在高并发架构里通常都有缓存这个环节,缓存系统的设计就是为了承载高并发而生,你完全可以根据系统的业务特性,对那种写少读多的请求,引入缓存集群。
具体来说,就是在写数据库的时候同时写一份数据到缓存集群里,然后用缓存集群来承载大部分的读请求。这样的话,通过缓存集群,就可以用更少的机器资源承载更高的并发。
比如说上面那个图里,读请求目前是每秒 2000/s,两个从库各自抗了 1000/s 读请求,但是其中可能每秒 1800 次的读请求都是可以直接读缓存里的不怎么变化的数据的。
那么此时你一旦引入缓存集群,就可以抗下来这 1800/s 读请求,落到数据库层面的读请求就 200/s。
同样,给大家来一张架构图,一起来感受一下:
以上的选择都是加硬件来应对高并发,下面来介绍一下代码层面来应对高并发的业务。
基于redis消息队列
消息队列,简称它为 MQ(Message Queue) 。听其名字我们可以简单把它理解成把要传输的消息数据放在队列中。消息队列有两个很重要的概念一个生产者,一个消费者。把数据放到消息队列中叫做生产者,从消息队列里边取数据叫做消费者。
光说概念,可能比较空,下面来说一下具体应用场景。
- 系统业务解耦。 具体场景: 比如购买电影票,这个电影票是有库存量的。用户点击购买电影票,但是没有规定时间内支付,则需要将这个库存量还原,不能让用户一直霸占着这个票,常用的解决方式是使用crontab每个1分钟检测一下购买时间是否超过15分钟。但是使用 crontab 会耗费服务器和数据库资源,当然最主要的还是数据库,因为服务器每间隔 1 分钟都要去执行脚本。脚本的内容又是去全量扫描数据库。相信大家都知道网站很大一部分的瓶颈就是数据库。 这个时候,我们试想可以在用户下单之后订单 id 记录到 redis队列里,进而监听 redis key 过期事件,然后从 redis 过期事件拿到订单 id 的数据,再进行还原库存量业务操作就可以了。
- 异步处理业务逻辑。 具体场景:用户注册,服务器收到用户的注册请求后,接受参数,保存用户信息。但是往往还会伴随发送邮件或者生成不同尺寸的头像等耗时操作。服务器处理多久,那用户也要等多久。为了用户体验,用户注册完之后,耗时的操作完全没有必要让用户继续等待,我们可以把这些耗时的操作记录对应的消息队列,后台异步处理。把注册成功的消息先返回给用户。
- 流量削锋。 具体场景:商城抢购活动,比如前 3 名访问的用户可以拿到奖品,我们可以借助redis把前 3 名的访问用户 Id 记录到 redis 队列中,其他用户再来请求就直接返回结果,避免用户直接请求数据库,然后后台异步读取 redis 的 3 名用户更新到数据中。
微服务
关于微服务应该就是把基础代码原子性,拆成一个独立的系统。这个大家可以去查一下相关的文章,我只是知道为什么用,但是还没怎么运用到开发环境中,这里就不做详细讲解。
启发
本文就是给大家介绍高并发到底是怎么回事儿,到底对系统哪里有压力,要在系统架构里引入什么东西,才可以比较好的支撑住较高的并发压力。
而且你可以顺着本文的思路继续思考下去,结合你自己熟悉和知道的一些技术继续思考,比如说,你熟悉 Elasticsearch 技术,那么你就可以思考,唉?在高并发的架构之下,是不是可以通过分布式架构的 ES 技术支撑高并发的搜索?
上面所说,权当抛砖引玉。大家自己平时一定要多思考,自己多画图,盘点盘点自己手头系统的请求压力。计算一下分散到各个中间件层面的请求压力,到底应该如何利用最少的机器资源最好的支撑更高的并发请求。
这才是一个好的高并发架构设计思路。
文章转载请说明出处:八零岁月 » 系统是如何一步一步支持高并发的
评论前必须登录!